前面在介紹 Entropy(熵) 的時候,我們提到它可以用來衡量資料的不確定性和驚喜程度,而在 Decision Tree 裡,我們利用 entropy 來判斷資料的純度或是不確定性。
延續這個概念,當我們在訓練分類模型時,我們需要一個能夠衡量預測結果與正確答案差異的指標。
除了常見的「準確率(Accuracy)」之外, Cross-Entropy(交叉熵) 是更常用、也更敏感的一個損失函數(loss function),它能夠幫助模型在訓練過程中更精確地學習。
以下就來談談 Cross-entropy~
以下為cross-entropy loss function的示意圖: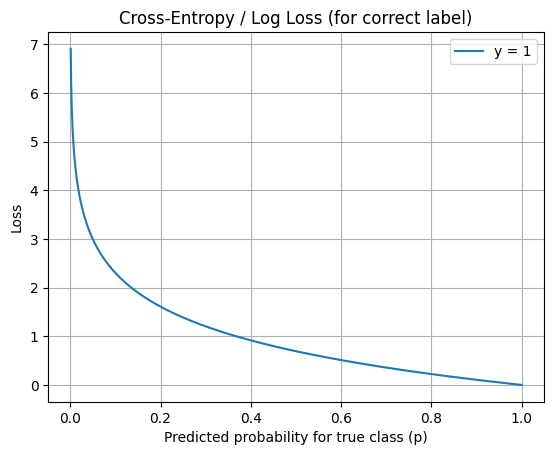
➔ KL divergence是在計算真實機率以及近似它的機率之間的差異,但是cross-entropy是在計算模型產出機率分布到真實機率之間的距離
以下為binary cross-entropy公式(針對所有資料):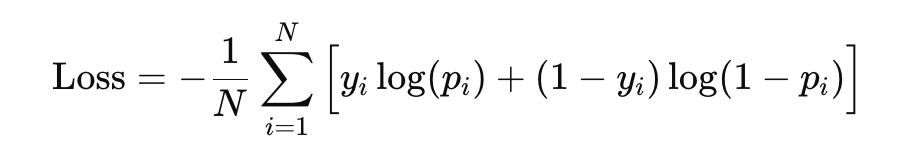
若是只要單看一個資料的損失,以下為公式(假設正確值為1):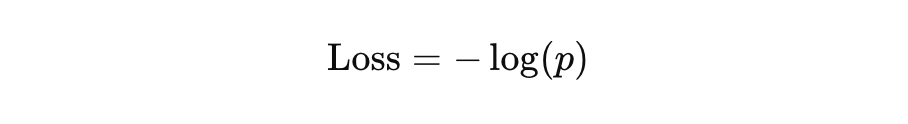
假設學生 A 和學生 B 都考了 90 分。
B 是靠實力答對所有題目,而 A 有一半題目是靠猜中得分。
從分數上看,兩人一樣,但實際學習成效卻不同。
Cross-Entropy就像考慮學生「答題信心」的指標,能反映模型的實際表現,而不只是對錯。
Reference 1
Reference 2
Reference 3


 iThome鐵人賽
iThome鐵人賽